개요와 목적
[백엔드/DB 지식] - DB Lock에 대한 이해와 MySQL Lock의 특징
해당 글에서는, 트랜잭션을 시작하면, 데이터를 DB Lock 설정으로, 다른 트랜잭션은 해당 데이터 접근을 막아 동시성 문제를 해결함을 배웠다.
이번 시간에는, 트랜잭션 격리성 레벨에 대해서 알아본다.
격리성 레벨에 따라 트랜잭션이 가지는 격리성(동시성 해결 능력)과 동시성(동시에 실행되는 정도)이 달라진다.
예를 들어 가장 강한 정도의 격리성 레벨, 완전히 순차적 실행이 되면 격리성(동시성 해결 능력)은 높아지지만 동시성은 너무 낮아져서 DB 처리 속도가 너무 느려진다. 한 트랜잭션이 읽기 작업만 해도, 다른 트랜잭션은 끝날 때까지 기다려야 하기 때문이다. (트랜잭션의 격리성과 동시성은 반비례 관계이다.)
각 격리성 레벨(커밋 후 읽기 수준, 반복 읽기 수준, 직렬화 수준)의 개념과 어떠한 장점, 한계성을 가지고 있는 지 알아보자.
1. Read Committed, 커밋 후 읽기 수준
커밋 후 읽기는 아래 동작으로 핵심 동시성 문제 두 가지를 해결한다.
- 커밋 된 데이터만 읽을 수 있다.(Dirty Raed 해결)
- 커밋 된 데이터만 덮어쓴다.(Dirty Wirte 해결)
1-a. 커밋된 데이터만 읽을 수 있다. Dirty Read 해결
<예시 Dirty Read 문제점>

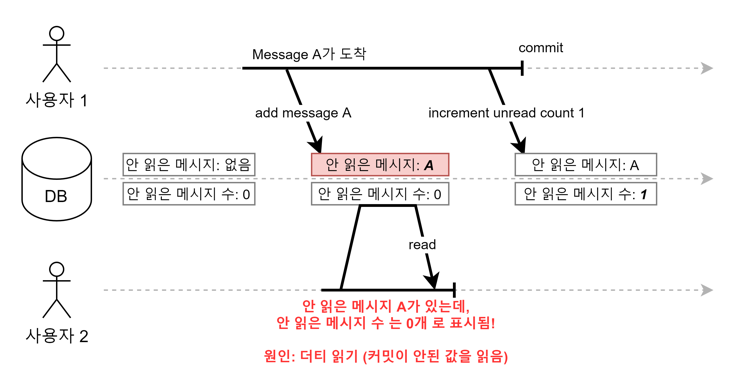
사용자1이 안 읽은 메세지 추가와 안 읽은 메세지 수+1 하는 트랜잭션을 진행하고 있었다. 사용자1이 안 읽은 메세지 추가만 한 상황에서 사용자2가 안 읽은 메세지와 안 읽은 메세지 수를 읽게 되었다. 그래서 안 읽은 메세지는 있는데, 메세지 수는 올라가지 않은 잘 못된 데이터를 얻게 되는 문제가 발생했다.
이 문제는 동시에 진행되어야 하는 트랜잭션(안 읽은 메세지 추가, 메세지 수+1)이 커밋 되기 전에 데이터를 읽는 것을 허용했기 때문에 생기는 Dirty Read이다.
<예시 Dirty Read 방지>
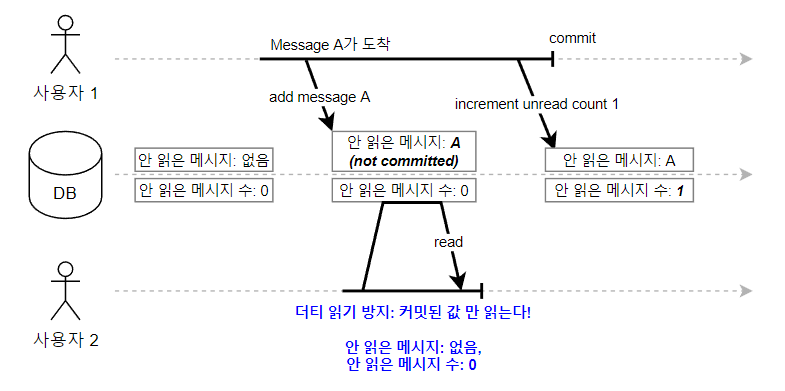
동시에 완료되어야 하는 명령어의 모음 트랜잭션이 커밋 되기 전에는 읽기를 방지함으로써 Dirty Read를 방지할 수 있다.
1-b. 커밋이 완료된 데이터만 수정가능 Dirty Write 해결
<예시 Dirty write 문제점>

위 예시는 아직 커밋 되지 않은 트랜잭션 도중에 다른 사용자가 write하여 생기는 문제이다. 사용자1이 구매자와 이메일수신자를 둘 다 입력 커밋하기 전에 사용자2가 끼어들어서, 구매자 정보가 엉망이 되는 문제가 발생했다. 이러한 Dirty Write문제를 방지 하기 위해서는 사용자1이 구매자와 이메일 정보를 커밋 완료할 때까지, 사용자2가 구매자 정보 입력에 접근하지 못하도록 막아야 한다.
<예시 Dirty Write 방지>
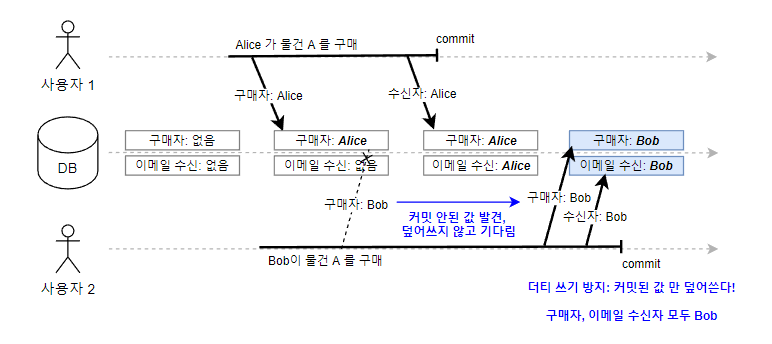
구매자와 이메일 수신자 작성(트랜잭션)이 완전히 커밋 된 데이터만 다른 트랜잭션이 작성할 수 있다
트랜잭션 커밋이 완료된 데이터만 수정가능. Dirty Wirte 방지
1-c. Read Committed(커밋 후 읽기)의 한계 -Non-Repeatable Read
Read Committed 단계에서 Dirty Read, Write 동시성 문제를 방지할 수 있었지만, 해결하지 못한 동시성 문제가 있다. 그것은 Non-RepeatableRead(비 반복 읽기)이다.
<예시 Non-RepeatableRead(비 반복 읽기)>

사용자2는 커밋이 완료된 데이터만 읽었음에도, 총합이 2500원(실제는 2000원)이라는 잘못된 데이터를 읽게 되었다.
이러한 문제는 비정상 응답을 잠깐 허용한 후에, 사용자2가 새로고침함으로 해결되는 문제일 수 있다. 하지만, 작동의 시간이 오래 걸리는 데이터 통계 작업의 경우 문제가 된다. 전체 데이터를 기반으로 데이터 통계 분석 작업을 진행 할 때, 시간이 오래 걸린다. 기존의 데이터를 기반으로 통계 분석 작업을 하는 도중 업데이트 된 데이터가 읽히게 된다면, 정확한 작업을 수행할 수 없게 된다.
2. Repeatable Read, 반복 읽기 수준
2-a 커밋 후 읽기의 Non-Repeatable 한계 해결
위 커밋 후 읽기 격리 수준이 해결하지 못한, 비 반복 읽기를 해결할 수 있는 격리 수준이 반복 읽기 격리 수준이다. 반복 읽기 격리 격리 수준은 스냅숏 격리를 사용하여 "비 반복 읽기” 문제를 해결한다. 스냅숏 격리는, 트랜잭션마다, txid(트랜잭션id)를 부여한다. 그리고 각 트랜잭션은 txid가 생성된 시점 커밋이 완료된 데이터로 데이터를 고정하여 제공한다. 데이터마다 여러 버전의 값을 관리하는 스냅숏 격리 방식은 다중 버전 동시 제어(MVCC)라고도 불린다.
예시를 통해서 스냅숏 격리의 작동 원리를 알아보자.
<예시 스냅숏 격리 사용>
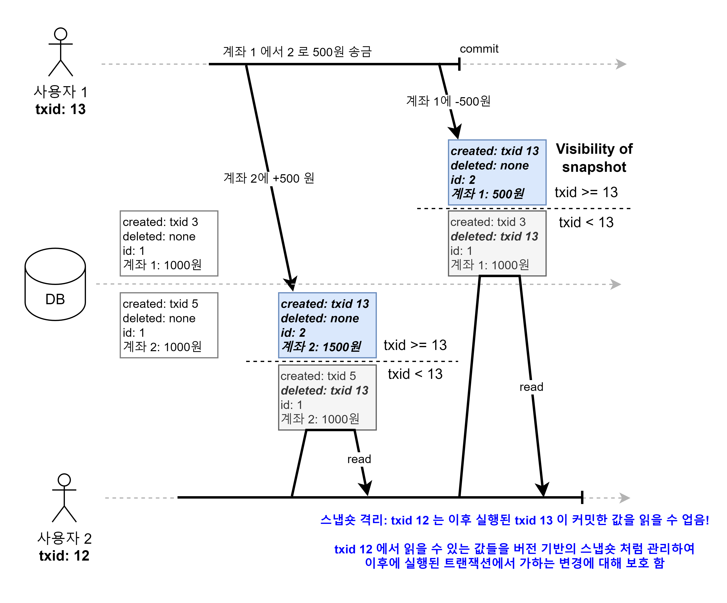
사용자 2의 txid는 12이고 사용자 1의 txid는 13이다. 사용자 2의 트랜잭션이 사용자 1보다 먼저 실행되었다. 스냅숏 격리로 사용자 2는 자신의 트랜잭션을 시작한 시점의 데이터를 사진처럼 가지고 있다. 그래서 사용자 1의 commit은 사용자가 가지고 있는 데이터에 영향을 미치지 못한다. txid-12의 계좌1에 1000원 계좌 2 1000원이라는 데이터는 사용자2가 커밋하기 이전까지는 사용자 2에게 절대 변하지 않는 데이터로 유지되는 것이다.
+ 반복읽기격리수준에서도 물론 두 트랜잭션이 같은 로우의 데이터를 수정하는 것을 방지해준다. 새로운 행을 추가하는 것은 막지 않는다. 따라서 똑같은 범위 쿼리를 실행했을 때 이후에 추가된 행이 발견될 수도 있다.
이는 MySQL8.0의 innoDB 기본값이다.
3. Serializable 직렬화 수준
Serializable 수준은 한 트랜잭션에서 읽고 쓰는 데이터에는 다른 트랜잭션의 모든 접근을 금지한다. 가장 단순하면서, 가장 엄격한 격리 수준이다.
Reference
모든 사진 출처:https://medium.com/@10x.developer.kr/db-트랜잭션-격리-수준-그림과-예시로-쉽게-이해하기-1편-5bef68de8b7b
https://zzang9ha.tistory.com/381
https://medium.com/@10x.developer.kr/db-트랜잭션-격리-수준-그림과-예시로-쉽게-이해하기-1편-5bef68de8b7b
'Web Sever 개발과 CS 기초 > DB 지식' 카테고리의 다른 글
| DB Lock에 대한 이해와 MySQL Lock의 특징 (0) | 2022.10.17 |
|---|---|
| 정규화(1,2,3,BNCF) 쉽게 이해하기 (0) | 2022.10.01 |
| 데이터베이스 구성 요소와 키(PK, FK)에 대한 이해 (0) | 2022.10.01 |
| DB Index 이해하기 (0) | 2022.10.01 |
| Transaction과 ACID 쉽게 이해하기(+MySQL transaction 설정 방법) (0) | 2022.10.01 |



